
今回はPythonとSeleniumを使って、Webスクレイピングの強力なテクニックであるXPathについて紹介します。
XPathはHTML要素を特定するための強力な言語であり、Webページからデータを抽出するのに役立ちます。
では、具体的な例を交えてXPathの使い方を紹介していきましょう。
目次
1.XPathとは?
XPathを使用することで、要素の階層関係や属性を使って、特定の要素を簡単に特定できます。
XPathではHTMLなどの階層構造を'/'(スラッシュ)を使って表します。
たとえば、//h1はドキュメント内のすべての<h1>要素を選択しますし、
//div[@class='content']はclass属性がcontentであるすべての<div>要素を選択します。
2.階層構造の表現例
また、以下のようなHTMLドキュメントの階層構造は、
<!DOCTYPE html>
<html>
<body>
<h1>Python selenium</h1>
<p>スクレイピング</p>
<h2>
<a href="https://www.google.com/">検索サイト</a>
</h2>
</body>
</html>
このようになります。
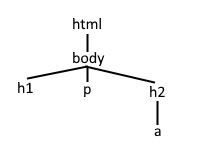
HTMLの階層構造
これについて、この中のaタグをXPathで表現すると、
/html/body/h2/a
となります。
このように、XPathを使用すると、HTMLやXMLの要素、属性値を簡単な構文で表現できます。
3.Chromeデベロッパーツールを使ってXPathを見つける方法
XPathを正確に記述するには、まず対象となる要素を特定する必要があります。
Google Chromeのデベロッパーツールを使ってXPathを見つける方法を紹介します:
Webページで右クリックして、「検証」を選択します。
デベロッパーツールが表示されたら、Ctrl + F(またはMacの場合はCmd + F)を押して検索バーを開きます。
XPathを見つけたい要素のHTMLコードを右クリックし、「Copy」から「Copy XPath」を選択します。
4.Seleniumを使用したXPath指定での要素の取得
(1)指定した要素を1つだけ取得する場合には、
driver.find_element(By.XPATH, value=指定したXPath)
のようにfind_element()を使用します。
(2)同様に、指定した要素を複数取得する場合には、
driver.find_elements(By.XPATH, value=指定したXPath)
のようにfind_elements()を使用します。
(3)属性名と属性値で属性指定して条件をつけて取得する場合には、
driver.find_element(By.XPATH, value="//タグ名[@属性名=属性値]")
のような書式で記載します。
たとえば、一例として、Gogle検索窓をXPath指定にて要素取得し、その窓に"abc"と入力し検索実行(Enterキークリック)するような例は以下のようになります。
(selenium ver.4.6以降の場合)
from selenium import webdriver
from selenium.webdriver.common.by import By
######################################################################
driver = webdriver.Chrome() ######################################################################
#指定したURLに遷移する
driver.get("https://www.google.co.jp")
#Google検索窓をxpath指定し要素取得
xpath = "//textarea[@class='gLFyf']"
element = driver.find_element(By.XPATH, value=xpath)
#検索窓に"abc"と入力
element.send_keys("abc")
#Enterキークリック
element.submit()
# タブを閉じる
driver.close()
driver.quit()
(4)ここで、先程の書式に対してタグ名を*にすると、すべてのタグ名に対して属性指定して取得することができます。
具体的には、
driver.find_element(By.XPATH, value="//*[@属性名=属性値]")
のような書式で記載します。
(5)さらに属性名も*にすると、すべてのタグ名、属性名に対して属性指定して取得することになります。
書式は、
driver.find_element(By.XPATH, value="//*[@*=属性値]")
のようになります。
(6)タグ内のテキストを指定して要素を取得する場合には、
driver.find_element(By.XPATH, value="//*[text()=指定する文字列]")
のような書式で記載します。
(7)複数の条件を指定して要素を取得する場合には、
driver.find_element(By.XPATH, value="//*[条件1 and 条件2]")
のような書式で記載します。
(8)抜き出した要素のn番目の要素を取得する場合には、
driver.find_element(By.XPATH, value="//*[position()=n]")
のような書式で記載します。
上記(7)、(8)の一例として、先程の例のコードのxpath指定の箇所に複数条件と順番指定を兼ねて、
and position()=1
を追加してみると以下のようになります。
(実行した結果は先程と同じになります)
(selenium ver.4.6以降の場合)
from selenium import webdriver
from selenium.webdriver.common.by import By
######################################################################
driver = webdriver.Chrome() ######################################################################
#指定したURLに遷移する
driver.get("https://www.google.co.jp")
#Google検索窓をxpath指定し要素取得
xpath = "//textarea[@class='gLFyf' and position()=1]"
element = driver.find_element(By.XPATH, value=xpath)
#検索窓に"abc"と入力
element.send_keys("abc")
#Enterキークリック
element.submit()
# タブを閉じる
driver.close()
driver.quit()
また、ドライバーの設定方法の違いだけになりますがSelenium ver.4.6以前の場合の例は、以下に載せています。
以上が、PythonとSeleniumを使ってXPathを活用する基本的な方法です。
XPathは非常に強力なツールであり、Webスクレイピングの幅を広げるのに役立ちます。
それでは、XPathを使ってデータを効率的に収集する楽しさを味わってください!
成功を祈っています!